Telefonica internship
Catastrophic forgetting
During October 2017 and December 2017 I have done an internship at Telefonica R&D department, working with Joan Serra. It’s been 6 years since I collaborated with him, and I am happy to have worked again. One can learn a lot from Joan, particularly when it comes to his sound research methodology and writing skills. It was good to shift a bit from music and work on a more general topic in machine learning. This time it was catastrophic forgetting.
J. Serra, D. Suris, M. Miron, and A. Karatzoglou, “Overcoming catastrophic forgetting with hard attention to the task” International Conference on Machine Learning 2018 (submitted)
A draft of the paper is already on arxiv and you can take a look.
What is catastrophic forgetting?
Ideally we want machines to learn in a sequential fashion, accumulating the knowledge learned in previous tasks, and using it to help future learning. In the more specific deep learning context, catastrophic forgetting is an undesired but natural behaviour of neural networks when trained to solve more than one task. By these means, catastrophic forgetting is related to other machine learning problems such as incremental learning and multitask learning.
So what was the approach? Actually, it was Joan’s idea on introducing the id of the task as an input into the network, in other terms, putting hard attention to the task. In paralel to the network, the task id is encoded as a set of embeddings which after a gating mechanism become almost binary. This is multiplied element-wise with the activations of each layer in the network, protecting weights which were important for previous tasks, and, thus, not forgetting. Then, through a regularization parameter which enforces sparsity, the network can compress its capacity to the point of allowing the remaining capacity for the future tasks.
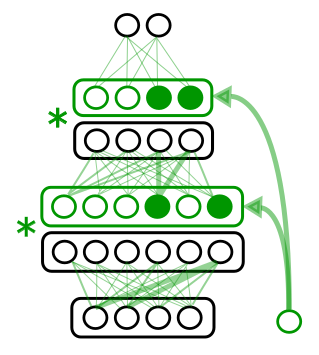
I was glad to contribute on implementing or improving state of the art methods. It was real fun to have it a go with PathNet and Progressive Networks which were two approaches published by researchers in DeepMind.
Then benchmark and the evaluation is much more exhaustive than the previous papers. It is done not on two or three, often very similar datasets/tasks, but on seven very different tasks.
BLOG
research, news, deep learning, machine learning, catastrophic forgetting, paper